专题一——重参数化
重参数化技巧
一、重参数化涉及的网络架构
1.编码器-解码器架构
(1)工作流程
·图片->编码器->低维隐变量分布->解码器->高维隐变量分布
(2)变分自动编码器(VAE)
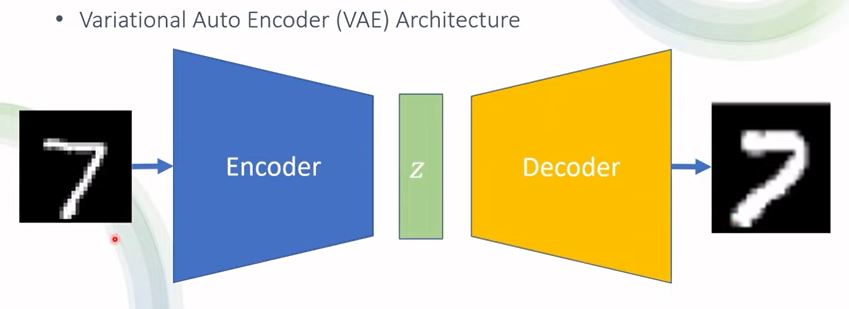
①模型目标
·并非完全进行图片重构,而是生成与输入样本类似的新样本。
·从高斯分布中采样\(z\),解码后即生成新样本。
②问题
·通过一个随机采样的样本,反向传播并不会进行导数的估计。
③解决方案
·重参数化
2.重参数化
(1)流程
①采样\(z \sim N(\mu, \sigma)\),该分布由均值、方差进行参数化。
②假如\((\mu, \sigma)\)是已知的,则可通过在标准正态分布采样\(z'\),应用变换\(z = \mu + \sigma z'\),获得对分布\(N(\mu, \sigma)\)的采样。
③\(\epsilon \sim N(0, 1), g_{\mu, \sigma}(\epsilon) = \mu + \epsilon \sigma\),即得\(z = g_{\mu, \sigma}(\epsilon)\)采样。
(2)重参数化与反向传播的关系
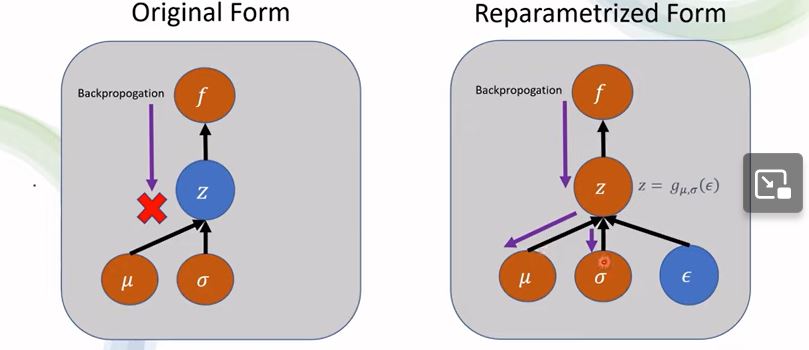
·对于未经重参数化的计算过程,反向传播不能通过“随机结点”\(z\)。
·对于经过重参数化的计算过程,令\(z = g(\mu, \sigma)(\epsilon)\),则反向传播可以顺利进行。
二、重参数化的数学原理
1.VAE
·\(z\)的采样是在\(x\)的条件下进行的(conditioned on x)。
·因此,\(z\)所属的分布的均值、方差也应该依赖于输入\(x\),即记为\(\mu_x, \sigma_x\).
·\(\phi = \{\mu_x, \sigma_x\}\)
2.带期望的损失函数
·损失函数/最小化目标:\(\mathbb{E}_{p(z)}f_{\theta}(z) = \int_zp(z)f(z)dz\)
·取梯度:\(\nabla_{\theta}\mathbb{E}_{p(z)}f_{\theta}(z) = \nabla_{\theta} [\int_zp(z)f_{\theta}(z)dz]\)
·由莱布尼茨积分法则:\(\nabla_{\theta}\mathbb{E}_{p(z)}f_{\theta}(z) = \int_zp(z)[\nabla_{\theta}f_{\theta}(z)]dz = \mathbb{E}_{p(z)}[\nabla_{\theta}f_{\theta}(z)]\)
3.损失函数梯度的理解
·\(\nabla_{\theta}\mathbb{E}_{p_{\theta}(z)}[f_{\theta} (z)]
\newline = \int_z[\nabla_{\theta}p_{\theta} (z)f_{\theta}(z)dz]
\newline = \int_{z}[f_{\theta}(z)\nabla_\theta p_{\theta} (z)dz] + \int_z[p_{\theta} (z) \nabla_\theta f_{\theta} (z)dz]\)
·上述公式中,第一项的\(\nabla_{\theta}p_{\theta}(z)\)难以计算,而重参数化使其可以显式计算。
4.损失函数的改造
·将\(\mathbb{E}_{p_{\theta}(z)}[f_{\theta}(z)]\)改造为\(\mathbb{E}_{p(\epsilon)}[f_{\theta}(g_{\theta}(\epsilon, x))]\),则只需从标准正态分布\(p(\epsilon) = N(0, 1)\)中采样。
·此时:\(\mathbb{E}_{p(\epsilon)}[\nabla_{\theta}f_{\theta}(g_{\theta}(\epsilon, x))]\)显然是可以进行梯度计算、反向传播的。