专题二——三类状态空间模型
课程:State Space Model(S4, S5, S6/Mamba) Explained by Anastasia Borovykh
链接:youtube
专题二——三种状态空间模型
一、目标
1.输入序列:\(\bold{u} = [u^1, \cdots, u^L], u^t \in \mathbb{R}^d\)
2.典型任务
(1)预测下一token\(u^{L + 1}\)
(2)序列分类
3.序列长度\(L\)可以非常巨大,即大模型中的“上下文窗口”(context window)。
4.性能之外的研究方向
·各层的计算复杂度
·并行程度,即最少的时序化操作次数。
二、常见框架回顾
1.循环架构——用于时间序列的经典方法
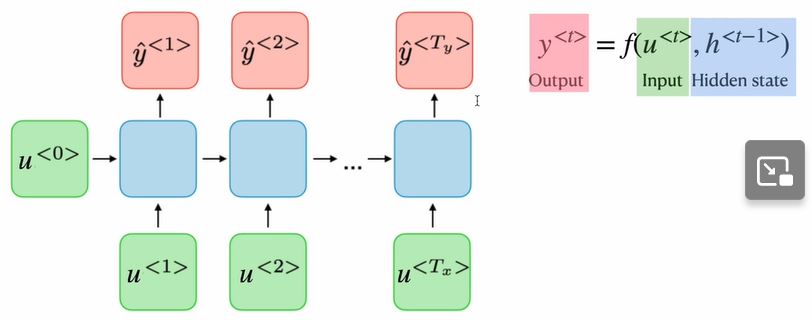
(1)数学公式
公式:\(y^{t} = f(u^t, h^{t - 1})\)
·理解:当前输入token\(u^t\)、上一时刻隐藏态\(h^{t - 1}\),经函数\(f\)作用得到当前输出\(y^t\)。
(2)优缺点
①优点
·计算复杂度:假设\(h = f(Wh + Wu), y = g(Wh), W \in \mathbb{R}^{d \times d}\),则各层时间复杂度为\(O(Ld^2)\)。
·自回归推理代价较低
②缺点
·非并行化:时序化本质,当前状态依赖于前一时刻状态。
·梯度消失(gradient vanishing)问题:序列过长时,难以保留较早的历史信息。
2.Softmax自注意力机制
(1)数学公式
\(softmax(\frac{(\bold{u}W^Q)(\bold{u}W^K)^T}{\sqrt{d}})\bold{u}W^V, W^Q, W^K, W^V \in \mathbb{R}^{d \times d}\)
(2)多头注意力
·\(MultiHead = Concat(head_1, \cdots, head_h)W^O\)
·\(head_i = softmax(\frac{(\bold{u}W^Q)(\bold{u}W^K)^T}{\sqrt{d}})\bold{u}W^V, W^Q, W^K, W^V \in \mathbb{R}^{d \times d}\)
(3)注意力映射
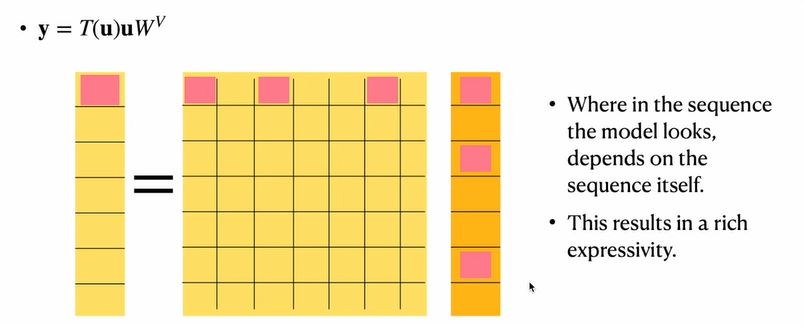
(4)优缺点
①优点
·并行化:矩阵乘法可高度并行化
·加速运算技巧:Flash Attention等计算技巧可以加速运算。
②缺点
·时间复杂度:矩阵乘法\(\mathbb{R}^{L \times d} \times \mathbb{R}^{d \times L}\)的时间复杂度为\(O(L^2d)\)
·训练、推理代价:若序列较长,则训练、推理代价巨大。
三、状态空间模型
1.目标
·具有Transformer的并行化程度,实现高效的并行化训练。
·具有RNN的内存效率,按照循环形式进行推理。
2.一般数学公式
\(x'(t) = Ax(t) + Bu(t)\)
\(y(t) = Cx(t) + Du(t)\)
·\(x(t) \in \mathbb{R}^H\):隐藏态。
·\(y(t) \in \mathbb{R}^d\):当前输出。
·\(u(t) \in \mathbb{R}^d\):当前输入。
·\(A \in \mathbb{R}^{H \times H}\):状态矩阵。
·\(B \in \mathbb{R}^{H \times d}\):输入矩阵。
·\(C \in \mathbb{R}^{d \times H}\):输出矩阵。
·\(D \in \mathbb{R}^{d \times d}\):前馈矩阵(feed-through matrix)。
3.常数步长离散化与循环形式
\(x_k = \bar{A}x_{k - 1} + \bar{B}u_k\)
\(y_k = \bar{C}x_k + \bar{D}u_k\)
(1)双线性离散化
\(\bar{A} = (I - \Delta / 2A)^{-1}(I + \Delta / 2A)\)
\(\bar{B} = (I - \Delta / 2A)^{-1}\Delta B\)
\(\bar{C} = C\)
\(\bar{D} = D\)
(2)零阶保持离散化
\(\bar{A} = e^{\Delta A}\)
\(\bar{B} = (\Delta A)^{-1}(e^{\Delta A} - I)\Delta B\)
\(\bar{C} = C\)
\(\bar{D} = D\)
[注]上述离散化操作得到了隐藏状态规模有限的循环推理形式。
4.并行化
(1)公式展开
·展开\(x_k, y_k\)的推导公式:
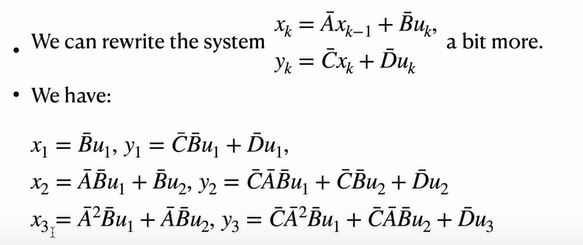
·将上述展开写成矩阵形式:
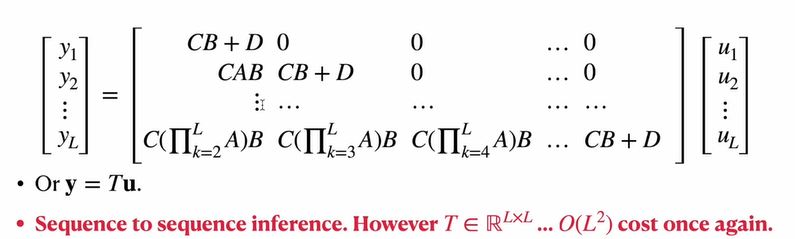
·注意到:变换矩阵\(T \in \mathbb{R}^{L \times L}\),故计算开销为\(O(L^2)\),比较昂贵。
(2)卷积与快速傅里叶变换
·将公式重写为卷积形式:
\(\bold{y} = \bar{K} * \bold{u}, \bar{K} = (\bar{C}\bar{B}, \bar{C}\bar{A}\bar{B}, \cdots, \bar{C}\bar{A}^{L - 1}\bar{B}) \in \mathbb{R}^{L}\)
·已知卷积核\(\bar{K}\),根据快速傅里叶变换,可将计算复杂度降低至\(O(LlogL)\).
5.优缺点
(1)优点
·卷积视角:提供并行化、高效训练,复杂度为次平方复杂度。
·循环视角:提供了快速的自回归生成,单个token的推理复杂度与序列长度无关。
四、SSM层的各项参数
·隐藏层架构:
\(x_k = \bar{A}x_{k - 1} + \bar{B}u_k\)
\(y_k = \bar{C}x_k + \bar{D}u_k\)
·需要学习的参数:\(A, B, C, D, \Delta\)
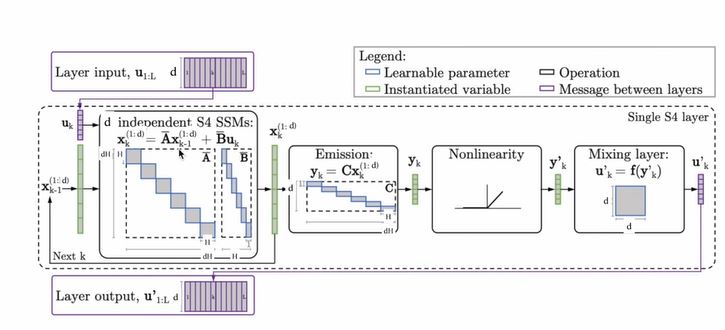
1.S4模型
(1)多维度问题
①SSM针对单个维度
·每个SSM针对的是输入序列的单个维度。
·每个输入通道先被映射为\(H\)维隐藏态,最终投影回到一维输出,然后应用非线性激活函数。
②逐位置线性混合层(position-wise linear mixing layer)
·用于连接独立特征,产生输出序列。
③模型可训练参数:\(A^h, B^h, C^h, D^h, \Delta^h, h = 1, \cdots, d\)
④可视化