专题一——选择状态空间模型
专题一——Mamba/S4模型
授课教师:Umar Jmail
一、序列建模简介
1.目标
- 将输入序列映射到输出序列。
- 连续映射(音频):将连续输入信号\(x(t)\)映射为连续输出信号\(y(t)\)。
- 离散映射(文本):离散输入序列映射到离散输出信号。
2.用于序列建模的模型
(1)RNN
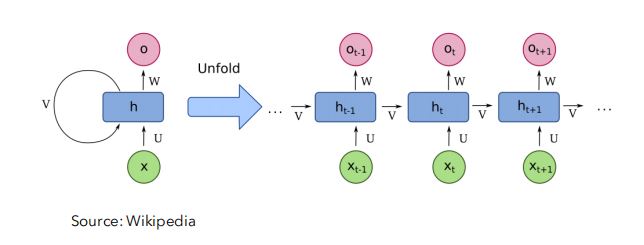
①计算流程
- \(x_1, x_2,\cdots\):隐藏状态
- \(h\):隐藏状态
- 隐藏状态初始化为\(0\),之后第\(t\)个时间步的输出\(o_{t}\)由输入\(x_{t}\)和隐藏态\(h_{t}\)决定,隐藏态\(h_{t + 1}\)由\(x_{t}\)和\(h_{t}\)共同决定。
②理解
- 训练时间复杂度:\(O(N)\),无法并行化。
- 推理时间:对每个token,推理时间是恒定的。
- 问题:梯度爆炸、梯度消失。
(2)CNN
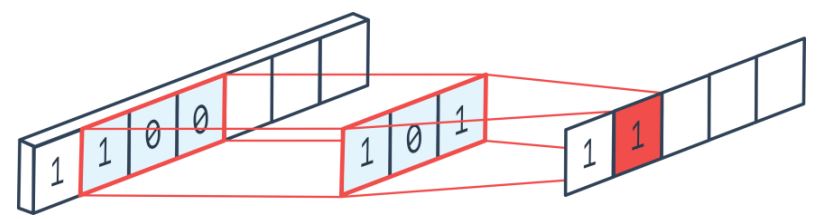
- 固定的上下文窗口。
- 每个输出使用相同的内核(卷积核),容易并行化。
(3)Transformer
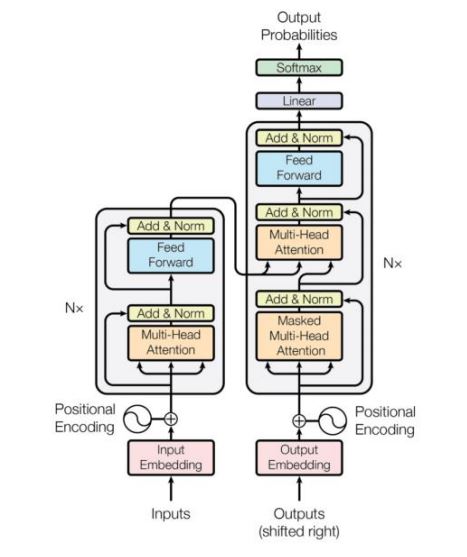
- Softmax注意力涉及矩阵乘法,可以并行化。
- 上下文窗口:由输入序列、掩码定义,有限的上下文窗口。
- 训练时间复杂度:\(O(N^2)\)。
- 推理时间复杂度:对于每个token,复杂度为\(O(N)\),原因是计算第\(i\)个输出token时,需要进行\(i\)对键-值对的点积计算。
- 各个token的线性推理代价,导致模型不适用于长序列的处理。
3.序列建模的理想情形
- 并行化:并行化训练。
- 规模化:对于长序列,计算开销、存储开销能够按照线性方式进行扩张。
- 常数推理代价:对于每个token,能用\(O(1)\)的计算开销、存储开销进行推理。
二、状态空间模型
[注]下列\(1 \sim 5\)仅考虑一维情况,之后拓展至高维情形。
1.定义
①数学定义
\(h'(t) = Ah(t) + Bx(t)\)
\(y(t) = Ch(t) + Dx(t)\)
- \(x(t)\):输入信号。
- \(y(t)\):输出信号。
- \(h(t)\):状态表示。
②理解
- 上述模型为线性模型。原因是表达式中均为线性关系。
- 上述模型是时间不变的,原因是矩阵\(A, B, C, D\)均不随时间变化。
2.一元状态模型
(1)假设与思考
①假设:定义中\(A, B, C, D, x(t), y(t)\)均为数而非向量。
②思考:为获得\(t\)时刻的输出\(y(t)\),首先需寻找一个函数\(h(t)\),以描述系统在各个时间步的状态;但该函数难以求解。
(2)微分方程求解过程
①离散化基本思想
- 设步长为\(\Delta\),此处并非显式求解\(h(t)\),而是近似计算\(h(t_k) = h(k\Delta)\)。
- 近似计算方法——一阶欧拉法:\(b(t + \Delta) = b(t) + b'(t) \Delta\)。
- 导数\(b'(t)\)可由仅含\(t\)的显式函数的式子进行替换,代入一阶欧拉公式即可完成近似计算。
②微分方程离散化求解
- 由导数定义:\(h(t + \Delta) \simeq \Delta h'(t) + h(t)\)
- 连续状态空间模型:\(h'(t) = Ah(t) + Bx(t)\)
- 迭代计算\(h(t + \Delta)\):\(h(t + \Delta) \simeq \Delta(Ah(t) + Bx(t)) + h(t)\newline = (I + \Delta A)h(t) + \Delta Bx(t) \newline = \bar{A}h(t) + \bar{B}x(t)\)
其中:
\(\bar{A} = I + \Delta A\)
\(\bar{B} = \Delta B\)
3.Memba实际涉及的状态模型
(1)公式
①原始公式
\(h'(t) = Ah(t) + Bx(t) \cdots (1a)\)
\(y(t) = Ch(t) \cdots (1b)\)
②离散化方法
\(h_t = \bar{A}h_{t - 1} + \bar{B}x_t \cdots (2a)\)
\(y_t = Ch_t \cdots (2b)\)
③导数近似计算方法:零阶保持方法(Zero-Order Hold, ZOH)。
④步长\(\Delta\):通过梯度下降进行学习,是可学习参数。
(2)循环计算
①循环公式
\(h_t = \bar{A}h_{t - 1} + \bar{B}x_t\)
\(y_t = Ch_t\)
②循环计算步骤
\(h_0 = \bar{B}x_0\)
\(y_0 = Ch_0\)
\(h_1 = \bar{A}h_0 + \bar{B}x_1\)
\(y_1 = Ch_1\)
(3)问题:上述形式的循环计算公式不适合训练,因为无法并行计算。
4.状态空间模型的卷积操作
(1)循环公式的展开
\(h_0 = \bar{B}x_0\)
\(y_0 = Ch_0 = C\bar{B}x_0\)
\(h_1 = \bar{A}\bar{B}x_0 + \bar{B}x_1\)
\(y_1 = Ch_1 = C\bar{A}\bar{B}x_0 + C\bar{B}x_1\)
\(\cdots\)
\(y_k = C\bar{A}^k\bar{B}x_0 + C\bar{A}^{k - 1}\bar{B}x_1 + \cdots + C\bar{A}\bar{B}x_{k - 1} + C\bar{B}x_k\)
(2)卷积
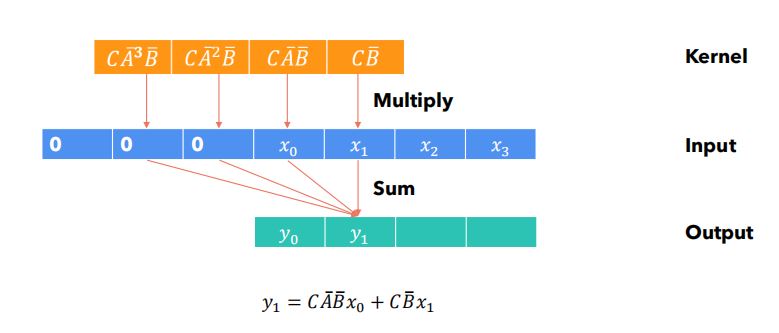
- 观察上述展开式,可以发现:使用卷积核\(\bar{K} = (C\bar{B}, C\bar{A}\bar{B}, \cdots, C\bar{A}^{k}\bar{B}, \cdots)\)对\(x_0, \cdots, x_k\)进行卷积\(y = x * \bar{K}\),可以得到输出\(y_k\).
(3)优势
- 并行化训练:使用卷积计算进行并行化训练,各token的输出互不依赖。
- 常数时间推断:使用递归公式进行推断,逐个token进行推断,每个token推断的计算开销、存储开销均为常量。
5.跳跃连接
(1)Memba状态空间模型
- Memba状态空间模型的循环计算公式为:
\(h'(t) = Ah(t) + Bx(t)\)
\(y(t) = Ch(t)\)
- 此处不使用公式\(y(t) = Ch(t) + Dx(t)\),原因是:\(Dx(t)\)一项可以视为输入到输出的跳跃连接。
- \(Dx(t)\)与隐藏状态、时间步无关,故无需进行建模。
6.高维计算
(1)基本思想
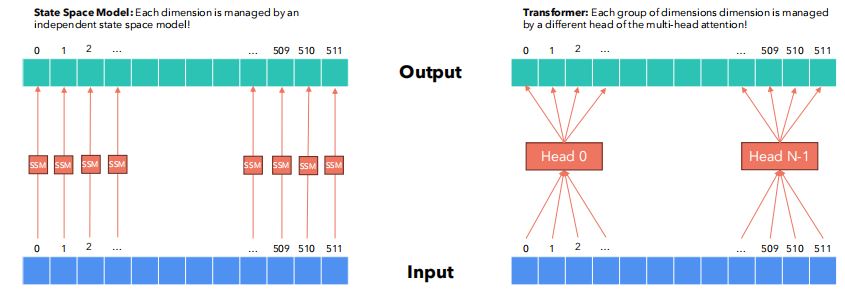
- 状态空间模型:输入向量的每个维度,分别由一个独立的状态空间模型进行管理。
- 多头注意力:每组维度由一个不同的注意力头进行管理。
7.矩阵\(A\)的重要性
- 矩阵\(A\)的作用:捕捉过去状态的信息,以建立新的状态;并决定了当前状态的信息如何向后传递。
- 因此,对于矩阵\(A\)的选择及其重要。对于语言模型而言,下一个token应依赖于之前所有token,之前的token序列组成了提示(prompt)。
- Memba:使用HIPPO理论,确保矩阵\(A\)取得较好的表现。
8.矩阵\(A\)的实现
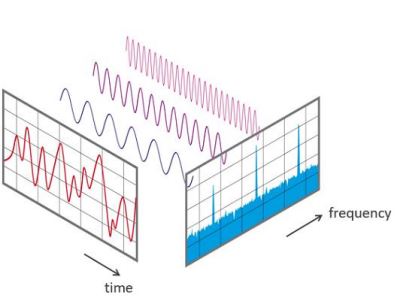
(1)傅里叶变换
- 将信号分解为正弦函数,不同幅值、频率的正弦函数之和对原信号函数形成了好的近似。
(2)HIPPO理论
- 使用Legendre多项式,对原函数进行分解近似。
- 建立矩阵\(A\)的方式是:把现在为止看到的输入信号,近似分解为Legendre多项式,用Legendre多项式的系数向量对矩阵\(A\)进行构造。
(3)傅里叶变化与HIPPO理论的区别
- 傅里叶变换:一致地关注到现在为止的所有信号。
- HIPPO理论:更早的信号强度符合指数衰减,因此隐藏态\(h(t)\)对于近期看到的token而言,捕捉到的信息更多一些。
- 如下图所示:对于离\(t\)时刻较近的信号,\(h(t)\)捕捉到的信息更多,重构得到的信号波形更接近真实情况;对于远离\(t\)时刻的信号,\(h(t)\)捕捉到的信息更少,重构失真情况更明显。
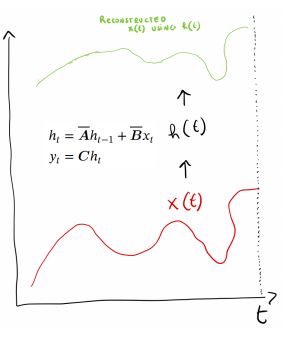
- 事实上,使用HIPPO矩阵对\(A\)进行初始化,可以大幅度提高模型性能。

三、Mamba
1.研究动机
在下列两种任务中,vanilla状态空间模型、S4模型表现欠佳,这是Memba提出的动机。
(1)选择复制
①时移复制
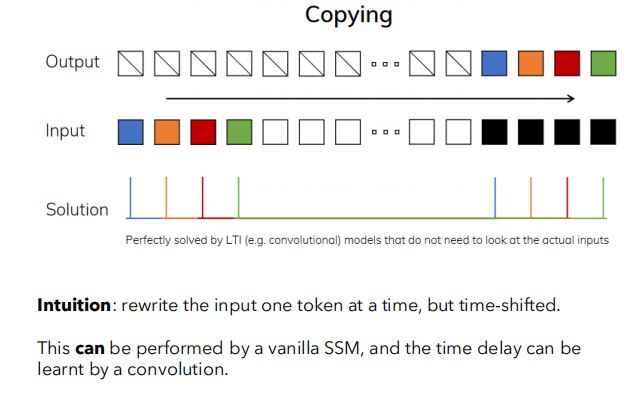
- 对于一个完整片段的时移复制任务,vanilla SSM可以完成该任务,卷积核可以学到时间差。
②选择复制

- 对于若干离散token选择性复制到一个连续输出片段的任务,vanilla SSM表现欠佳。
- 原因:选择复制依赖于上下文相关的推理(context-aware reasoning),但是vanilla SSM是时间不变的,即循环公式中\(A, B, C, D\)矩阵对于每个生成的token而言,都是相同的。
(2)感应头(Induction Head)
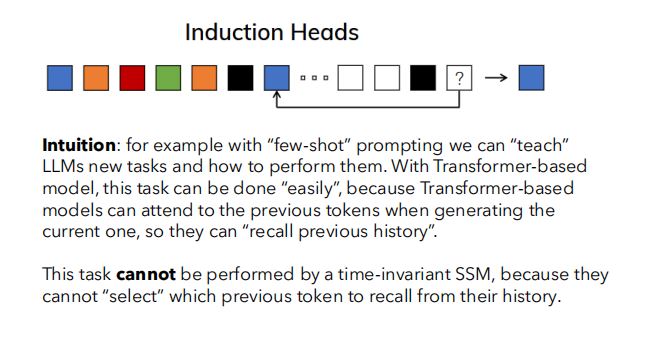
- 模型需要从过往输入的历史中召回信息(recall previous history),以处理当前的输入。
- 对于few-shot提示,应该给大模型进行新任务的教学,告诉大模型如何执行新任务。
- 对于基于Transformer的模型而言,“召回过去历史”很容易实现,原因是注意力机制可以注意到之前的所有token。
- 对于时间不变的SSM而言,上述任务难以实现原因是时间不变SSM无法选择哪些过往的token需要被召回。
2.Mamba——选择性状态空间模型
(1)S4算法(Structured State Space Model)

- 输入、输出:形状为\((B, L, D)\)
- \(B\):batch size
- \(L\):序列长度
- \(D\):每个输入向量的维度(即每个token的嵌入表示维度,与Transformer中\(d_{model}\)意义相同)
- \(N\):隐藏态\(h\)的维度。
- 变换矩阵\(A\):\((D, N)\)
- \(\Delta\):\((D, )\),由模型学习而来的离散步长,针对token的每个嵌入表示维度,分别学习一个离散步长。此处离散步长是时间不变的。
(2)S6算法(SSM + Selection)

- 基本特点:状态空间模型具有选择性,即参数矩阵\(A, B, C\)随着输入时间步\(t\)的变化而变化。
- \(s_B(x), s_C(x)\):分别将\(x\)的每个token的嵌入表示从\(D\)维线性投影至\(N\)维。
- \((B, L, N)\):表示对于每个输入token,分别有一个不同的矩阵\(B\),以及一个矩阵\(C\)。
- 注意到,此时模型不再是时间不变的,因此只能运用原始循环公式\(h_t = \bar{A}h_{t - 1} + \bar{B}x_t\)以及\(y_t = Ch_t\),原因是卷积核不是固定的。
3.扫描操作
(1)前序和

- \(Sum[i] = \sum_{k = 1}^{i}n[k]\)
- 注意到:\(Sum[i] = Sum[i - 1] + n[i]\)
(2)扫描操作

- 扫描操作与前序和操作具有异曲同工之处,即\(h_t\)由前一时刻隐藏态\(h_{t - 1}\),及当前时刻输入\(x_t\)共同决定。
- 每个\(h_t\)乘\(C\)矩阵,即得输出\(y_t\)。
(3)扫描操作的并行化技术(parallel scan)
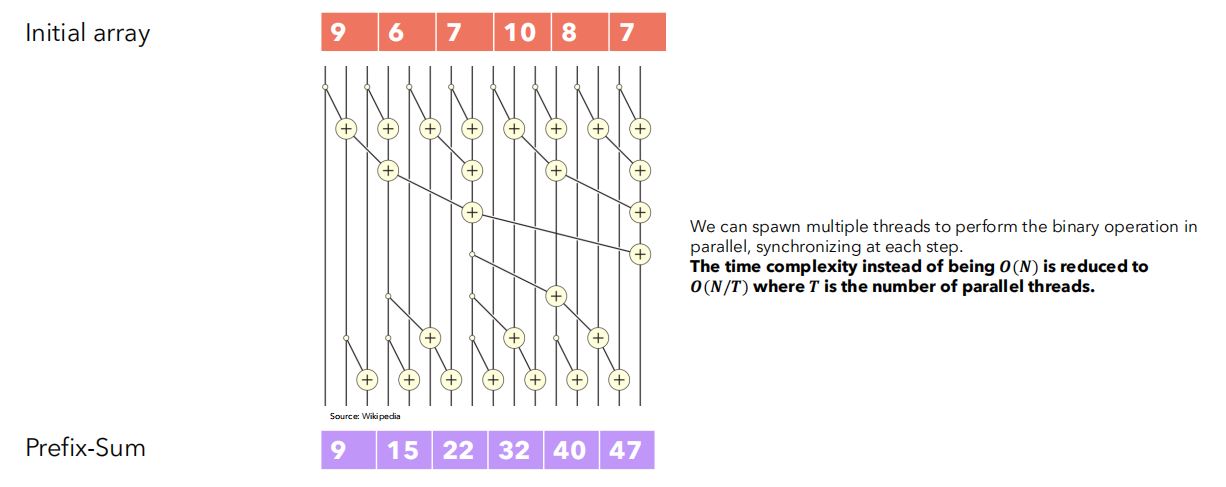
- 基本思想
- 只要循环计算涉及的操作具有结合性质,则可改变操作先后顺序,以实现并行化计算。
- 建立多个线程,实现并行求和。
- 中间图片有\(16\)个输入,\(8\)个线程。
- 先两两求和,然后求\(4, 8, 16, \cdots\)个元素一组的输入之和。
- 设\(T\)为线程数,则并行计算可将时间复杂度从\(O(N)\)降低到\(O(\frac{N}{T})\)。
4.并行扫描操作
(1)GPU的存储层次
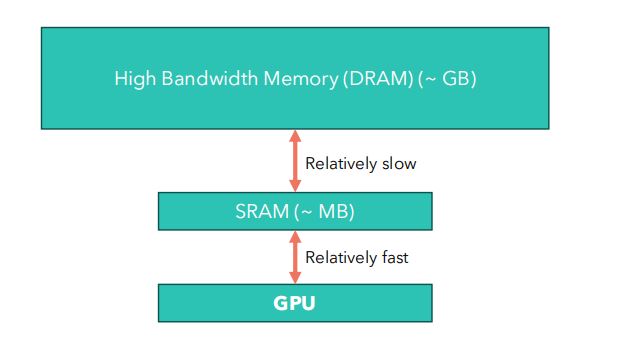

- GPU:巨大的计算单元,可以同时完成大量的并行计算。
- 两个主存
- DRAM:高带宽存储,以GB为单位,读写速度相对慢。
- SRAM:较小,以MB为单位,读写速度相对快。
- GPU计算过程
- 数据从DRAM复制到SRAM,然后GPU核心访问SRAM数据,进行计算,并将结果返回高带宽DRAM。
- GPU带宽
- 数据复制速度明显慢于计算速度。
- 内核运行缓慢,可能是因为正在进行大量复制,导致I/O速度限制内核速度。
(2)并行扫描基本思想
- 充分利用现代GPU的层次结构,使得并行扫描尽可能快。
- 隐藏状态放在I/O速率较高的SRAM中进行,SSM参数直接从HBM加载到SRAM,并在SRAM上进行离散化、循环计算操作,之后将形状为\((B, L, D)\)的输出写回HBM。
(3)内核融合(kernel fusion)
- 进行张量操作时,PyTorch将张量加载到GPU的SRAM中,执行操作(矩阵乘法、加法等),然后将结果写回HBM。
- 但是,如果对每个张量进行\(3\)次连续的操作,则每次操作结束,深度学习框架都会先把各次操作的计算结果写回HBM,进行下一次操作时再把HBM中的中间结果加载到SRAM,因此运行时间受到数据复制的影响而大幅度增加。
- 为了加速一系列连续操作,可以融合CUDA内核,使得一个CUDA核连续执行对同一张量的\(3\)次操作,无需写回中间结果,只需向HBM写回最终结果。
5.重计算(Recomputation)
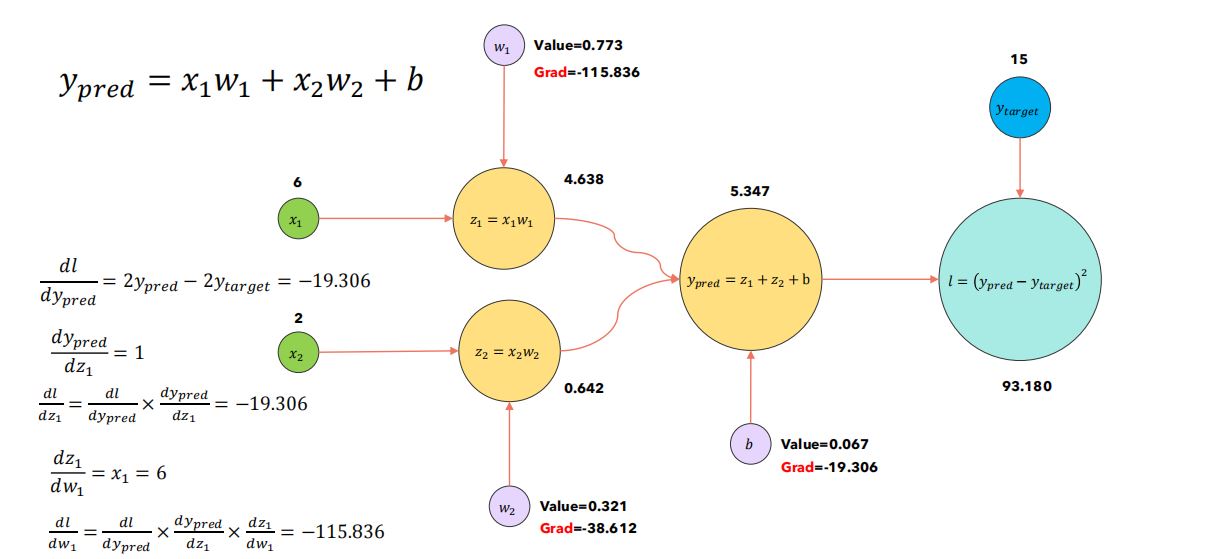
(1)计算图与输出缓存
- 训练深度学习模型时,模型被转化为计算图。
- 执行反向传播时,为了计算各个结点的梯度,需要缓存各个前向计算步骤的输出(即各个神经元结点的激活值/输出值)到HBM;使用缓存输出值时,又需要将数据从HBM加载到SRAM中,数据加载占用大量时间。
(2)重计算
- 思想:不缓存结点的输出值,而是在反向传播过程中重新计算各结点的输出值,以降低数据加载量。
- 结果:融合选择扫描层的内存需求与优化的、带FlashAttention的Transformer实现。
6.Mamba块
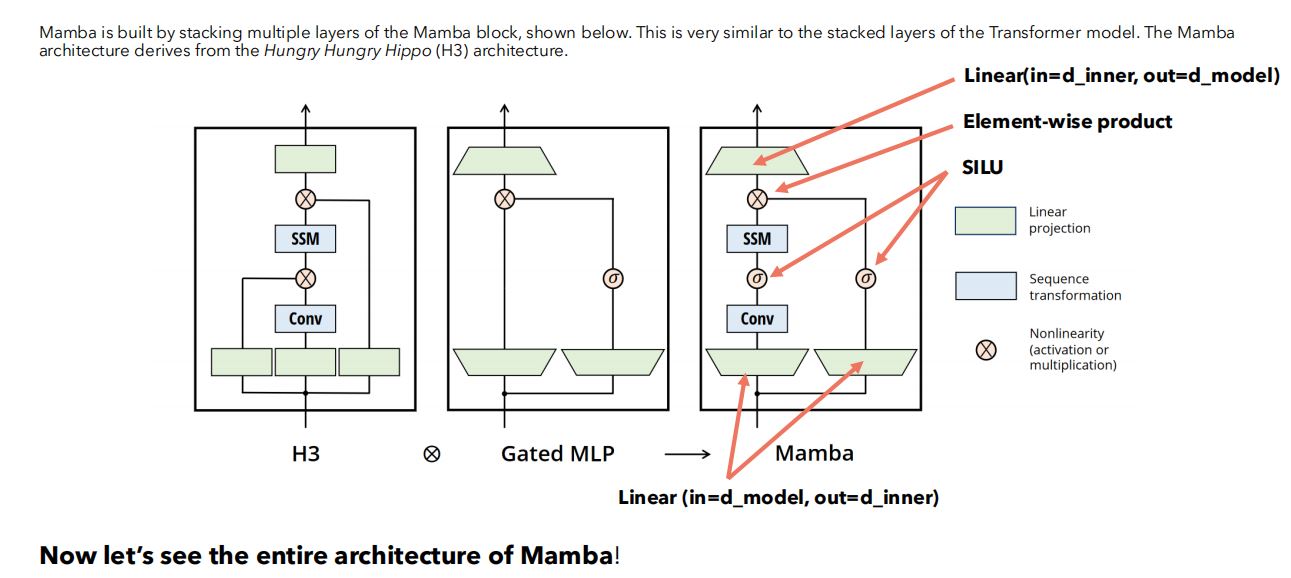
(1)Mamba
- Mamba由若干Mamba Block堆叠而成,类似于Transformer模型的stacked layers。
- Mamba架构来源于H3架构。
(2)Mamba块
- 输入经过两个线性投影,从\(d_{model}\)维度投影到\(d_{inner}\)维度,其中\(d_{inner}\)维度一般高于\(d_{model}\)。
- 一个投影结果先进行卷积、非线性激活,再应用SSM块;另一个投影结果直接进行非线性激活。
- 之后,上述两个结果作逐元素乘积,乘积经过线性投影层从\(d_{inner}\)维度回到\(d_{model}\)维度。
(3)Mamba块详细架构
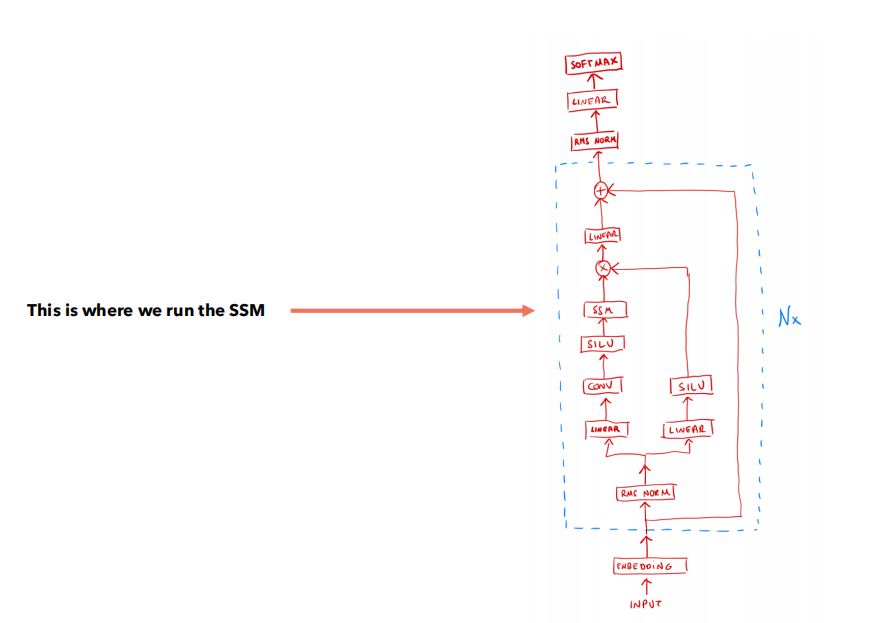
- 与之前图片相比,增加了RMS正则化层、跳跃连接。
7.Mamba的性能
(1)选择复制任务
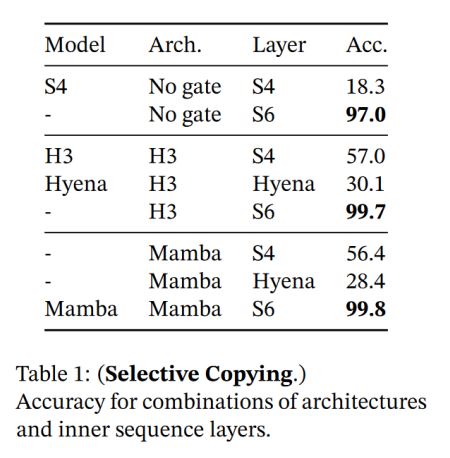
- 与S4, Hyena层相比,Mamba论文提出的S6层放在H3/S4/Mamba架构中,均能使得架构的性能得到显著提升。
- S6层能很好地解决选择复制问题。
(2)感应头任务
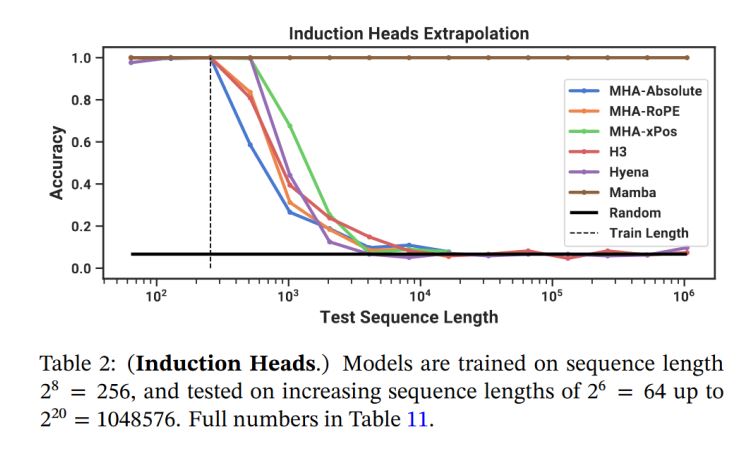
- 在感应头外推任务中,Mamba对应顶端的棕色折线,性能显著优于其他状态空间模型。
- 随着序列长度增加,Mamba在感应头任务上能够保持优越性能,可以期望Mamba在长序列任务上表现优异。
(3)尺度定律
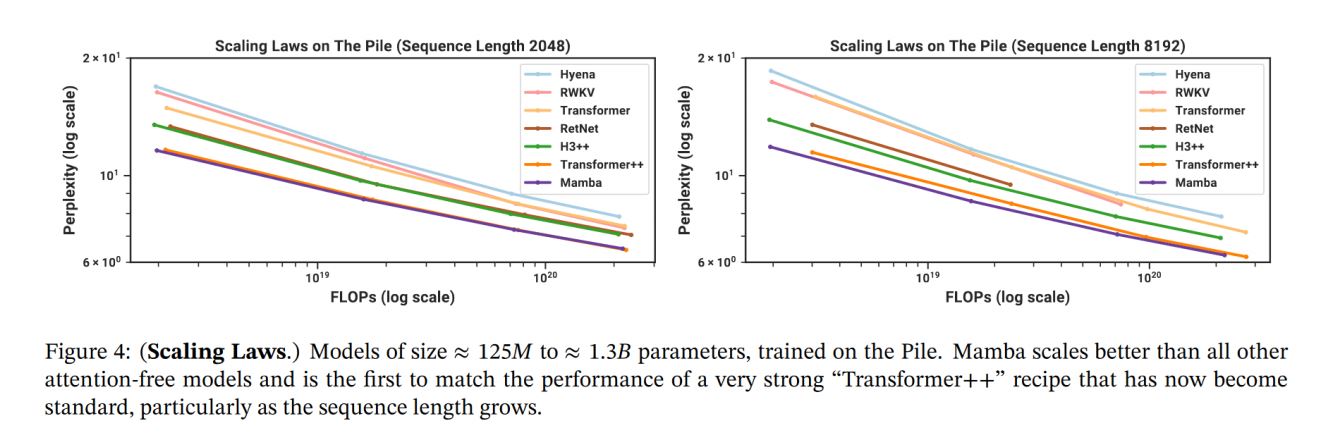
- Mamba与Transformer++(现有最好的Transformer)表现相当。