基于弱信息学习健壮的图神经网络
[论文标题] Learning Strong Graph Neural Networks with Weak Information
[发表期刊] KDD 2023
[论文链接] arxiv
[论文主题] 图神经网络 数据缺失 少样本学习
一、摘要
1.背景——图神经网络的优点与缺点
(1)优点:在许多图学习任务中取得优秀的性能(准确率)。
(2)缺点:输入图数据具有弱信息(weak information)问题时,图神经网络的性能会明显下降。
[注]弱信息问题:主要包含图结构不完整(边缺失)、图特征不完整、图标签不足等三类问题。
2.背景——对图神经网络弱信息问题的现有研究
(1)现状:绝大多数现有研究仅针对三类弱信息问题的某一个类别。
(2)问题:仅针对单个类别进行研究,在不同类型弱信息问题同时存在、相互影响的情形下无法获得较好的性能。
3.研究目的
设计一个有效的、原则性的方法,解决三类弱信息同时存在的图学习问题(GLWI, graph learning with weak information)。
4.具体工作
(1)基于本文的经验分析结果,得到了解决GLWI问题的两个关键点:
①允许长距离信息传播。
②允许信息传递到孤立结点。
[注]孤立结点(stray node):指的是度数为0,或者处于最大连通子图(largest connected component)以外其他子图中的结点。
(2)提出\(D^2PT\)架构
①双通道(dual-channel)架构
·第一个“通道”:在结构不完整的原始输入图上进行信息传递。
·第二个“通道”:在编码全局语义相似性的全局图上进行信息传递。
②设计原型对比对其算法(prototype contrastive alignment algorithm)
·功能:对两个通道学习得到的类级别原型(class-level prototypes)进行对齐。
·作用:不同的信息传递路径可以互相产生裨益,最终得到的模型可以较好地处理GLWI问题。
5.提出方法的有效性
·在8个真实世界benchmark数据集上的大量实验表明了本文提出方法的效率和准确率。
二、背景
1.图神经网络
【关键机制、问题分类与应用场景】
(1)关键机制
·消息传递
[注]消息传递:对邻域信息进行汇聚(即:对当前结点、邻域结点的特征进行加权求和,将结果作为当前结点的新的特征)。
·特征变换
[注]特征变换:对当前结点的特征进行非线性变换。
(2)问题分类
受益于消息传递、特征变换机制,图神经网络能够解决以下问题:
·节点分类
·链接预测(边预测)
·图分类
(3)应用领域
图神经网络在以下任务取得了巨大成功:
·药物发现
·欺诈检测
·知识归因(knowledge reasoning)
图神经网络近期一些的研究领域
·无监督表征学习
·对抗攻击
·结构搜索
【GNN涉及的基本操作】
(1)GNN涉及的原子操作
基于消息传递机制,GNN涉及两类原子操作
·P(propagation):从邻域结点进行信息聚合。
·T(transformation):通过可学习的非线性映射,对每个结点的特征分别进行变换。
(2)不同GNN对P/T函数及其顺序的设计
①常见的P(聚合)函数
·平均、求和、注意力
②常见的T(变换)函数
·MLP
③P/T操作的顺序
·主流GNN:遵循PTPT模式,即先传播再变换的PT层时序化叠加。
·少数GNN:先进行多轮的某种操作,再进行另一类操作,如PPTT/TTPP模式。
2.图神经网络的假设与现实
(1)关键假设
·观察到的数据(即GNN的输入数据)足够理想化,可以提供充足的信息(结构、特征、标签)供模型训练。
(2)现实——关键假设在现实世界中通常不成立
①现实世界数据通常从复杂系统中提取,通常包含不完整、不充足的信息。
·受到数据收集过程中隐私问题、人类操作错误的影响,真实世界的图数据中,某些边和结点经常会缺失,导致弱结构、弱特征问题。
②用于模型训练的标签信息不总是充分。
·导致弱标签问题。
3.解决GLWI问题的近期工作
【方法分类、共同问题】
(1)遗失信息恢复
·建立新的边进行图结构学习
·属性补全
·利用伪标签进行数据集扩充
(2)充分利用观测到的弱信息
·少标签泊松学习
·针对特征、图结构的知识蒸馏
(3)共同存在的问题
·绝大多数工作仅关注单一问题,而事实上弱结构、弱特征、弱信息问题经常同时出现。
【具体工作介绍】
(1)图结构学习——解决弱结构(不完整结构)问题
·目标:在学习主干网络GNN的同时,学习到一个经过优化的图结构。
·LDS模型、GEN模型的做法:使用伯努利模型/随机块模型,对邻接矩阵进行参数化,将概率模型和主干GNN进行联合训练。
IDGL/Simp-GCN的做法:引入标准学习(metric learning)技术,对原始图结构进行修正(revise)。
·Pro-GNN的做法:直接使用可学习参数对邻接矩阵进行建模,该参数与主干GNN进行交替的学习。
(2)属性补全(attribute completion)——解决特征不完整的问题
·目标:根据现有数据,恢复缺失数据。
·Spinelli等人:首先把基于GNN的自动编码器应用缺失数据补全。
·SAT:引入特征-结构分布匹配机制(feature-structure distribution matching machanism),用于解决结点特征补全问题。
·\(GCN_{MF}\):使用高斯混合模型,在GNN的第一个layer,对不完整的特征进行变换。
·HGNN-AC:使用拓扑嵌入表示(topological embedding)进行特征补全。
(3)标签高效的图学习(label-efficient graph learning)——解决图训练数据标签不充足的问题
·IGCN:先驱工作,在GNN上使用具有标签感知能力的(label-aware)低通图滤波,实现标签的高效性。
·M3S:充分利用聚类技术,提供额外的监督信号,用多阶段方法对模型进行训练。
·CGPN:使用泊松网络、对比学习进行标签高效学习。
·Meta-PN:生成高质量的伪标签,用标签传播技术对标签稀疏的训练样本进行增强。
(4)问题
·无一工作联合考虑三类数据缺陷问题。
·学习过程经过详细的设计,因此训练过程的计算开销巨大,损害了上述方法在大规模图上的效率。
三、问题定义
1.记号
[注]受时间限制,没有使用论文规定的符号字体。
·\(G = (V, E, X) = (A, X)\):具有结点属性(即特征矩阵\(\mathbf{X}\))的无向图。
·\(V = \{v_1, \cdots, v_n\}\):结点集合,规模为\(n\)。
·\(E\):边集合,规模为\(m\)。
·\(A \in \{0, 1\}^{n \times n}\):邻接矩阵。
·\(X \in \mathbb{R}^{n \times d}\):结点特征矩阵(每个结点特征维度为\(d\),矩阵第\(i\)行\(X_i\)表示结点\(v_i\)的特征向量)
·(结点)标签矩阵:\(Y \in \mathbb{R}^{n \times c}\),其中\(c\)是总的类别数。(\(Y_{ij} = 1\)表明结点\(v_i\)属于第\(j\)类)
·结点\(v_i\)的邻域集合:\(N_{v_i} = \{v_j | A_{ij} = 1\}\)
·正则化邻接矩阵:\(\tilde{A} = D^{-\frac{1}{2}}AD^{-\frac{1}{2}}\),其中\(D\)为对角度数矩阵,\(D_{ii} = \sum_jA_{ij}\)。
2.图神经网络
设结点\(v_i\)的输入表示、输出表示分别为\(\mathbf{h}_i^{(i)}, \mathbf{h}_i^{(o)}\)。
(1)传播操作P(propagation)
·\(\mathbf{h}_i^{(o)} \leftarrow P(\mathbf{h}_i^{(i)}, \{\mathbf{h}_j^{(i)}|v_j \in N_{v_i}\})\)
(2)非线性变换操作T(transformation)
·\(\mathbf{h}_i^{(o)} \leftarrow T(\mathbf{h}_i^{(i)})\)
(3)举例——GCN(Graph Convolution Network)
·传播操作(即对当前结点、邻居结点的表征进行简单的求和操作,各项权重相同):\(\mathbf{h}_i^{(o)} = \sum_{j}\tilde{A}_{ij}\mathbf{h}_j^{(i)}\)
·变换操作(即不含bias的单层MLP):\(\mathbf{h}_i^{(o)} = \sigma(W\mathbf{h}_j^{(i)})\)
(4)用P/T函数表示不同类型GNN
·按照P/T操作的堆叠方式,GNN可分为耦合(entangled)、非耦合(disentangled)类型。
①耦合GNN——PTPT
·两层GCN:\(\mathbf{H}^{(o)} = GCN(\mathbf{H}^{(i)}) = P(T(P(T(\mathbf{H}^{(i)}))))\)
②非耦合GNN——PPTT/TTPP
·两层SGC:\(\mathbf{H}^{(o)} = SGC(\mathbf{H}^{(i)}) = T(P(P(\mathbf{H}^{(i)})))\)
(5)P/T操作的次数
·传播步数(propagation step)\(s_p\):P操作执行的总次数。
·变换步数(transformation step)\(s_t\):T操作执行的总次数。
3.半监督结点分类(本文重点关注的任务)
(1)图中各类结点的集合
·结点集合:\(\mathbf{V}\)
·有标签(labeled)结点集合:\(\mathbf{V}_{L} \subset \mathbf{V}\),在\(\mathbf{V}\)中占比较小。
·无标签(unlabeled)结点集合:\(\mathbf{V}_{U} \subset \mathbf{V}\),在\(\mathbf{V}\)中占比较大。
(2)推理目标
·预测无标签结点\(\mathbf{V}_{U}\subset \mathbf{V}\)的标签。
(3)训练标签
·训练标签:\(\mathbf{Y}_L \in \mathbb{R}^{n_L \times c}, n_L = |\mathbf{V}_L|\)
4.弱信息图学习(GLWI, graph learning with weak information)
[注]下列图数据中:
·某集合/矩阵的上标为\(\hat{\space}\),表示该项输入数据是理想化的。
·某集合/矩阵的上标为\(\check{\space}\),表示该项输入数据是不充足的。
(1)理想图数据
[定义3.1](理想图数据)
·理想图数据:\(\hat{D} = (\hat{G}, \hat{Y}_L) = ((V, \hat{E}, \hat{X}),\hat{Y}_L)\)
·\(\hat{E}\):理想边集合,包含所有必要的边。
·\(\hat{X}\):理想特征矩阵,包含所有富含信息量的特征。
·\(\hat{Y}_L\):理想标签矩阵,包含足够的标签(数目为\(\hat{n}_L\)),且分布均衡。
·不完整边集:\(\check{E} \in \hat{E}\)。
·不完整特征矩阵:\(\check{X} = M ⊙ \hat{X}\),其中\(M \in \{0, 1\}^{n \times d}\),表示缺失特征对应的掩码矩阵。
[注]\(⊙\)表示两个矩阵主元素相乘。
·不完整标签矩阵:\(\check{Y}_L \subset \hat{Y}_L\),其中\(\check{n}_L \lt \lt\hat{n}_L\)
(2)基本GLWI场景
①弱结构(ws, weak structure)——某些结点之间的边缺失
\({D}_{ws} = ((V, \check{E}, \hat{X}),\hat{Y}_L)\)
②弱特征(wf, weak feature)——一部分结点的某些输入特征缺失
\({D}_{wf} = ((V, \hat{E}, \check{X}),\hat{Y}_L)\)
③弱标签(wl, weak label)——有标签结点较为稀疏 监督信号不足
\({D}_{wl} = ((V, \hat{E}, \hat{X}),\check{Y}_L)\)
(3)极端GLWI场景——弱结构、弱特征、弱标签问题共存
·\(D_x = ((V, \check{E}, \check{X}),\check{Y}_L)\)
四、解决GLWI问题的过程、思路与方法
【解决问题过程概览】
1.经验分析——GNN面临弱信息的表现和影响因素
(1)信息传递的重要性
·信息传播在减轻数据不完整性带来的影响时,作用十分重要。
·长距离信息传递不仅能帮助恢复缺失数据,还能进一步利用已有信息。
(2)弱信息情境下信息传递受阻
·模型架构的局限性和数据的缺陷,阻碍了不完整数据的信息传递过程。
·GNN在极端弱信息的情境下,性能衰退的主要原因是:不完整的图结构。(孤立结点与最大连通子图隔绝,阻碍了特征融合以及监督信号的传递)
2.\(D^2PT\)模型的提出
(1)提出思路
·根据经验分析得到的设计原则,提出该网络架构。
(2)目标
·通过实现高效的长距离传播、缓解孤立结点问题,使得模型能在弱信息场景下进行有效的信息传递。
(3)做法
①设计基于扩散的主干模型
·有助于增强表达能力,降低长距离消息传递的计算开销。
②通过连接语义相似的结点学习全局图
·允许孤立结点参与信息传播。
③应用双通道训练、对比原型对其机制
·充分利用全局图的知识,优化DPT主干网络。
【详细分析过程及其对模型设计的启发】
1.信息传递在GLWI中的作用
作者分别针对weak feature/weak label/weak structure三种情形,对信息传递的作用进行了分析。
(1)信息传递对弱特征(weak feature)的作用
①作用:信息传递可以利用上下文知识,自然地补全缺失特征。
②举例
·在引用网络中,目标结点(一篇论文是一个结点)只具有特征BERT/Text,这样的特征是不足以判定该文章的类型的。但是通过信息传递,邻居结点的特征GPT/XLNet/Sentence可以提供充足的信息,使得模型更容易判断目标结点是一篇NLP论文。
(2)信息传递对弱标签(weak label)的作用
①作用:将监督信号从标签结点传播到无标签结点。
②对于标签结点极其稀疏的图结构而言,十分需要高效的信息传递机制,让更多的无标签结点接受到来自有标签结点的正确的监督信号,从而进行特征修正。
(3)信息传递对弱结构的作用
①边的作用:是邻接结点进行信息交流的桥梁。
②不完整结构中消息传递的困难性:不完整结构中信息传递桥梁缺失,导致结点间消息传递困难。
[理解]
桥梁缺失的问题有两点:
一是消息传播路径延长。考虑一个由\(10\)个结点组成的环路,本来结点\(1\)和结点\(10\)互为邻居结点,只需\(1\)步P操作即可完成沟通;但如果它们之间的边发生缺失,则需\(8\)步P操作,才能完成二者的消息沟通,而且消息沟通时,来自对方结点的特征已经被严重稀释,造成“分散问题”(dilution problem)。
二是消息传播被完全阻隔。考虑一个连通图因消息缺失而成为二部图,则常规架构下两个子图间无法进行消息传递。
(4)总结
①信息传递的关键作用:传播上下文特征、传播监督信号。
②信息传递质量会大幅度受到不完整图结构的影响。
[启发思考]如何提高图结构的质量,减轻不完整图结构带来的影响,使得信息传递效率更高?
[理解]上述分析表明,如果只按照incomplete graph structure本身具有的边,进行信息传递,那么GNN的性能一定不会太好,这就为后文另外建立一个global graph,根据结点语义相似度(特征向量的相似度,比如余弦相似度或其他更高级的方法)建立全局图中connection的方法作出了铺垫。
2.长距离信息传递有益于GLWI
(1)长距离信息传递是对[启发思考]问题的一个有效回答
①在不变更网络架构、信息传递机制的前提下,长距离信息传递是对[启发思考]的一个有效回答。
②长距离信息传递,有利于信息缺失结点考虑更大范围的上下文结点,获得更充足的上下文知识,从而缓解数据缺失带来的影响。
(2)实验分析——确认较大的传播步数\(s_p\)有利于提高模型性能
[实验]
①实验设定
·作者对比了若干传播步数\(s_p\)不同的模型,对比它们在不同标签/边/特征缺失率之下的性能优劣。
·图2表明了实验结果,括号内的数字即该模型的传播步数\(s_p\)。
②实验结果与结论(图2(a) - 2(c))
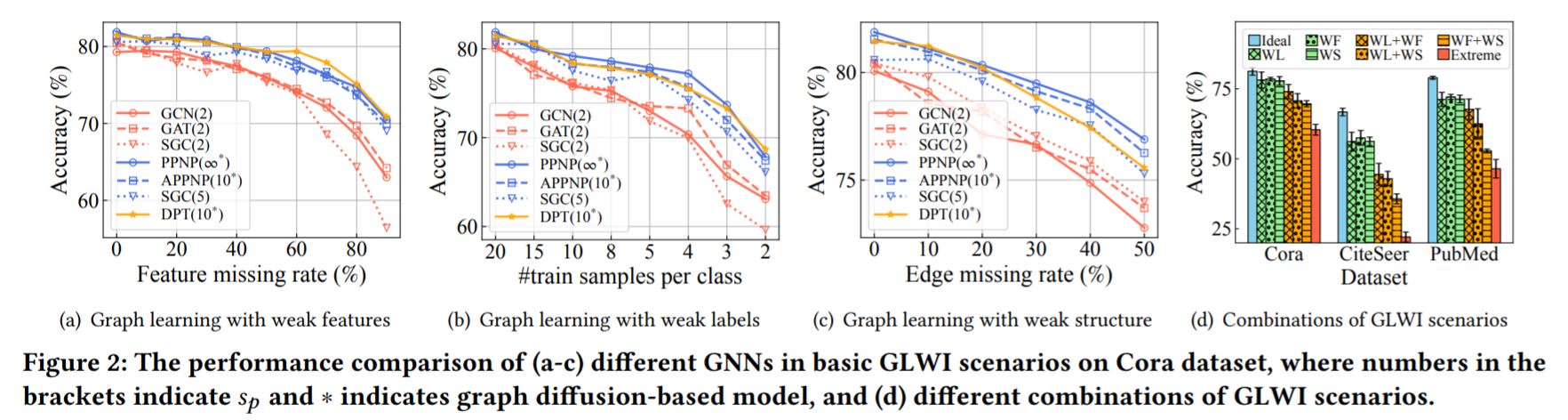
·结果一:在三种情形下,\(s_p\)更大的模型性能总体上好于\(s_p\)更小的模型。
·结论一:验证了长距离信息传递在GLWI场景中的有效性。
·结果二:随着数据不完整性上升,更大\(s_p\)与更小\(s_p\)的性能差距不断增大。
·结论二:表明了更大\(s_p\)模型在面临GLWI场景时,相对于更小\(s_p\)模型的优越性。
·结果三:其余超参数不变,\(SGC(s_p = 5)\)性能好于\(SGC(s_p = 2)\)。
·结论三:更大的\(s_p\)确实是性能增益的主要贡献因素。
·结果四:在\(s_p\)较大的模型中,具有图扩散机制的GNN性能更好。
[理解]
上述实验结果为\(D^2PT\)传播步数较大、引入图扩散机制的设计提供了参考。
[讨论]
①基于图同构理论:作者认为带有相似特征/标签的结点,在拓扑图中应该倾向于相互连接。该观点能支持长距离传播在特征补全、监督信号传递中的有效性。
②若\(s_p\)过大,则噪声信息将会不可避免地出现在感受野中,损害性能。
·在网格搜索中,发现\(SGC(s_p = 10)\)性能不如\(SGC(s_p = 5)\)。
③过大的\(s_p\)容易导致GNN的过平滑问题。
④实验结果表明:图扩散机制可以缓解过平滑问题(原因:每一个传播步骤,都添加了当前结点原始表征,作为残差连接),从而允许\(s_p\)更大一些。
3.孤立结点阻碍GLWI
(1)极端情况实验
①目的:研究较大\(s_p\)的模型在特征、标签、结构同时缺失的情况下,有怎样的表现。
②实验结果(图2(d))
·在特征、标签、结构同时缺失的情况下,模型即使\(s_p\)较大,但性能仍然急剧下降。
·WF + WS/WL + WS的性能下降比WF + WL严重很多,说明不完整的图结构是阻碍GLWI的主要因素。
(2)由实验结果引发的思考
①仅仅提高\(s_p\),对于极端GLWI场景而言,不能解决问题。
②图结构的质量大幅度影响消息传递的有效性。
(3)对“弱结构”问题的深入探究
①观察
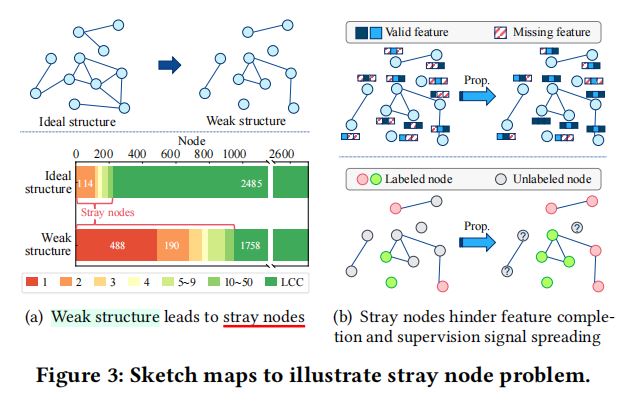
·理想图数据:绝大多数结点互相连通,形成最大连通子图。
·弱结构图数据:存在更多的孤立子图和孤立结点,最大连通子图的规模(结点占比\(64.9\%\))明显不如理想状况(结点占比超过\(90%\))。
②孤立结点阻碍特征补全。
③孤立结点阻碍信息传递。
·上述两个结论是显然的,感觉作者的这一段分析含金量不高,就不作叙述了。
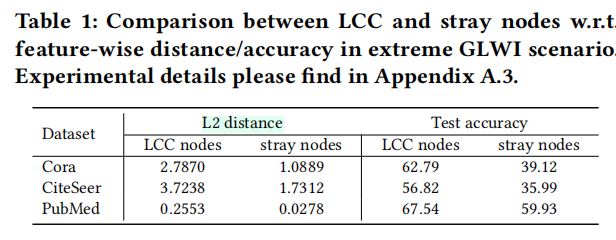
·下图通过最大连通分量、孤立结点间的特征向量距离,以及两类结点分别进行标签预测的测试准确率,佐证了上述两个结论。
4.分析过程带来的两点起启示
(1)允许长距离特征传播能够进一步弱化数据不完整性(结构、特征、标签)带来的影响。
(2)处理极端GLWI的关键是:解决最大连通分量之外孤立结点的低效信息传递问题。
【方法——提出基于图扩散的双通道对比学习GNN架构】
1.DPT(Diffused Propagation then Transformation)模型——解决长距离信息传递问题
(1)常见GNN的P/T堆叠方式及其计算开销
①耦合\(GNN\)
·由于传递、变换操作交替进行,因此随着\(s_p\)增长,传递、变换操作的次数都要增长,计算开销线性上升。
②非耦合\(GNN\)(先传播再变换)
·只需进行最终变换,故变换操作的计算开销是恒定的。
·部分\(GNN\)的传播代价随\(s_p\)线性增长,其余则只需一次传播即可实现任意\(s_p\)范围的覆盖,计算开销与\(s_p\)无关。
·因此作者采用的是非耦合设计范式,先传播再变换。
(2)\(DPT\)模型
①两个步骤
·基于图扩散的传播
·基于MLP的变换
②图扩散公式
\(\mathbf{X}^{(0)} = \mathbf{X}\)
\(\mathbf{X}^{(t + 1)} = (1 - \alpha)\tilde{A}\mathbf{X}^{(t)} + \alpha\mathbf{X}\)
\(\bar{\mathbf{X}} = \mathbf{X}^{(T)}\)
·\(\tilde{A}\):正则化邻接矩阵。
·\(\bar{X}\):完成信息传播的特征矩阵。
·\(T\):完成消息传播的总次数。
·\(\alpha \in (0, 1]\):重启概率。
[理解]
·结点的初始表征即输入特征向量。
·每轮迭代用正则化邻接矩阵确保梯度、特征向量各维度的数值都相对稳定,不会发生爆炸。
·\(+\alpha\mathbf{X}\)即残差连接项,每次迭代都添加当前结点的原始输入特征,保持了结点自身的特点,即使经过多轮迭代,不同结点的表征始终具有一定的差异,从而很好地缓解了过平滑(不同结点表征趋于混同)的问题。在NLP中有类似的思想和方法,比如对于线性/softmax注意力机制,添加残差连接可以让token更多地注意到自身,防止“注意力分散”(attention dilution)。
③变换公式
\(\mathbf{H} = MLP_1(\bar{\mathbf{X}}) = \sigma(\bar{\mathbf{X}}\mathbf{W}_1)\)
\(\bar{\mathbf{Y}} = MLP_2(\mathbf{H}) = softmax(\mathbf{HW}_2)\)
·\(\mathbf{H} \in \mathbb{R}^{n \times e}\):表征矩阵。
·\(\mathbf{W}_1, \mathbf{W}_2\):MLP中的可学习参数。
·损失函数:交叉熵损失,可以由\(\bar{\mathbf{Y}}\)和训练标签\(\mathbf{Y}_L\)进行计算。
[理解]
·模型在\(T\)步propagation后,最终才进行transformation,这是Diffusion Propagation then Transformation的命名由来。
2.双通道DPT(\(D^2PT\), Dual Channel Diffused Propagation then Transformation)
(1)基本思想与目的
·目的:解决孤立结点问题。
·关键做法:建立全局图,任意两个结点均互相连通->对原始图、全局图进行联合训练。
·结果:孤立结点可以进行充足的信息沟通。
(2)全局图构建、双通道特征融合步骤
①根据原始图上完成传播的特征\(\bar{\mathbf{X}} = \mathbf{X}^{(T)}\),建立增强全局图。
②在全局图(作为一个通道)、原图(作为另一个通道)上分别运行DPT算法。
③使用原型对比对其损失(contrastive prototype alignment loss)\(L_{cpa}\),对两个通道得到的特征进行正则化。
(3)全局图的形式化定义
①全局图的邻域——基于特征相似度构建的\(k\)近邻邻域
·设全局图的邻接矩阵为\(\mathbf{A}'\)
若\(s(\bar{\mathbf{X}}_i, \bar{\mathbf{X}}_j) \geq min(\tau(\bar{\mathbf{X}_i}, k), \tau(\mathbf{X}_j, k))\),则\(\mathbf{A}_{ij}' = 1\);
否则\(\mathbf{A}_{ij}' = 0\)。
·上式中,\(s(\cdot, \cdot)\)表示相似度函数;\(\tau(\bar{X}_i, k)\)表示所有特征向量中,与\(\bar{X}_i\)排名为\(k\)的相似度数值。
·上述定义保证了在全局图中,每个结点至少有\(k\)个邻居结点。
②在原始图、全局图上并行运行DPT算法
·对于全局图而言,正则化邻接矩阵为\(\tilde{\mathbf{A}}' = D'^{-1/2}\mathbf{A}'\mathbf{D}'^{-1/2}\)。
③同时针对全局图、原始图进行损失函数计算
·使用共享权重的MLP模型,即全局图、原始图的特征非线性变换(T(transformation))使用的是同一个MLP。分别对全局图的预测输出\(\bar{Y}'\)和原始图的预测输出\(\bar{Y}\),计算交叉熵损失\(L_{ce}', L_{ce}\)。
·该做法的作用是:让模型能够从两种视角(原始拓扑结构视角、全局语义相似度视角)捕捉信息,缓解孤立结点的影响。
(4)对比原型对齐(contrastive prototype alignment)
①朴素双通道模型
·尽管共享用于T(transformation)操作的MLP参数,但由于全局图、原始图的结构大相径庭,它们最终产生的结点表征仍然有较大的差异->导致模型不能从两个观点捕捉共同信息,并且监督信号的作用可能会紊乱。
·仅仅针对有标签结点进行交叉熵损失计算,在标签结点稀疏时可能遭遇过平滑问题。
②原型对比对齐算法
·目的:增强两个通道的语义一致性,并从无监督结点中获取监督信号。
·第一步:对特征进行线性映射
设从原始图、全局图得到的特征分别是\(\mathbf{H}, \mathbf{H}'\),首先使用共享的线性投影层作变换:
\(\mathbf{Z} = \mathbf{H}\mathbf{W}_3, \mathbf{Z}' = \mathbf{H}'\mathbf{W}_3\)
·第二步:针对原始图、全局图,分别计算各个类别的“原型”
\(\mathbf{p}_j = \sum_{i, argmax(\mathbf{\bar{Y}}_i) = j}\frac{s_iZ_i}{S_j}\)
\(\mathbf{p}'_j = \sum_{i, argmax(\mathbf{\bar{Y}}_i) = j}\frac{s_iZ_i'}{S_j}\)
上式中:
\(i\)是结点索引。
\(j \in [1, \cdots, c]\),表明模型预测结点\(v_i\)属于的类别。
对于有标签结点,\(s_i = 1\);对于无标签结点,\(s_i = max(\bar{Y}_i)\),表示预测置信度。
\(S_j\)是预测为类别\(j\)的所有结点的权重\(s_i\)之和。
·第三步:计算基于InfoNCE的对比原型对齐损失(类别级,class-level)
\(L_{cpa} = -\frac{1}{2c}\sum_{j = 1}^c(log\frac{f(\mathbf{p}_j, \mathbf{p}_j')}{\sum_{q \neq j}f(\mathbf{p}_j, \mathbf{p}_q')} + log\frac{f(\mathbf{p}_j, \mathbf{p}_j')}{\sum_{q \neq j}f(\mathbf{p}_q, \mathbf{p}_j')})\)
上式中,\(f(\mathbf{a}, \mathbf{b}) = e^{\frac{cos(\mathbf{a}, \mathbf{b})}{\tau}}\)为余弦相似度函数,\(\tau\)为温度超参数。
(5)\(L_{cpa}\)相对于传统交叉熵函数的好处
·允许模型学到类别level的信息,进一步利用标签。
·计算复杂度由\(O(en^2)\)降低为\(O(ec^2)\)。
(6)模型的学习目标
·需要最小化的损失函数:\(L = L_{ce} + \gamma_1L'_{ce} + \gamma_2L_{cpa}\)
·由两个通道各自预测标签的交叉熵损失,以及二者预测标签的对比原型对齐损失共同叠加得到。
五、实验结果
总体情况:\(D^2PT\)模型架构不仅在极端GLWI场景取得了state-of-the-art的结果,在基本的GLWI场景性能也十分优越,此外时间、空间复杂度与现有的许多模型相比,是比较不错的。
1.实验设定
(1)实验数据集
·共8个真实世界图数据集,包括Cora/CiteSeer/PubMed/
Amazon Photo/Amazon Computers/CoAuthor CS/
CoAuthor Physics/ogbn-arxiv.
(2)GLWI场景构建
·弱结构:随机去除途中\(50%\)的边。
·弱特征:随机选择特征矩阵\(50%\)的元素,用0填充。
·弱标签:对于每个类别,选择5/20/2%个(依不同数据集而定)标签用于训练,30个标签用于验证,其余用于测试。
·极端GLWI:融合上述三种方法进行构建。
(3)Baseline
①传统GNN
·GCN/GAT/APPNP/SGC
②带有图结构学习功能的GNN
·Pro-GNN/IDGL/GEN/SimP-GEN
③带有特征补全功能的GNN
·M3S/CGPN/Meta-PN/GRAND
④用于效率efficiency分析的可放大GNN
·GraphSAGE/ClusterGCN/PPRGo/GAMLP
(4)测试细节
·对每项实验,运行\(5\)轮,记录平均测试准确率、标准差。
·使用网格搜索,在验证集上搜索最佳参数。
2.模型在不同GLWI场景下的表现
(1)关键任务——极端GLWI场景
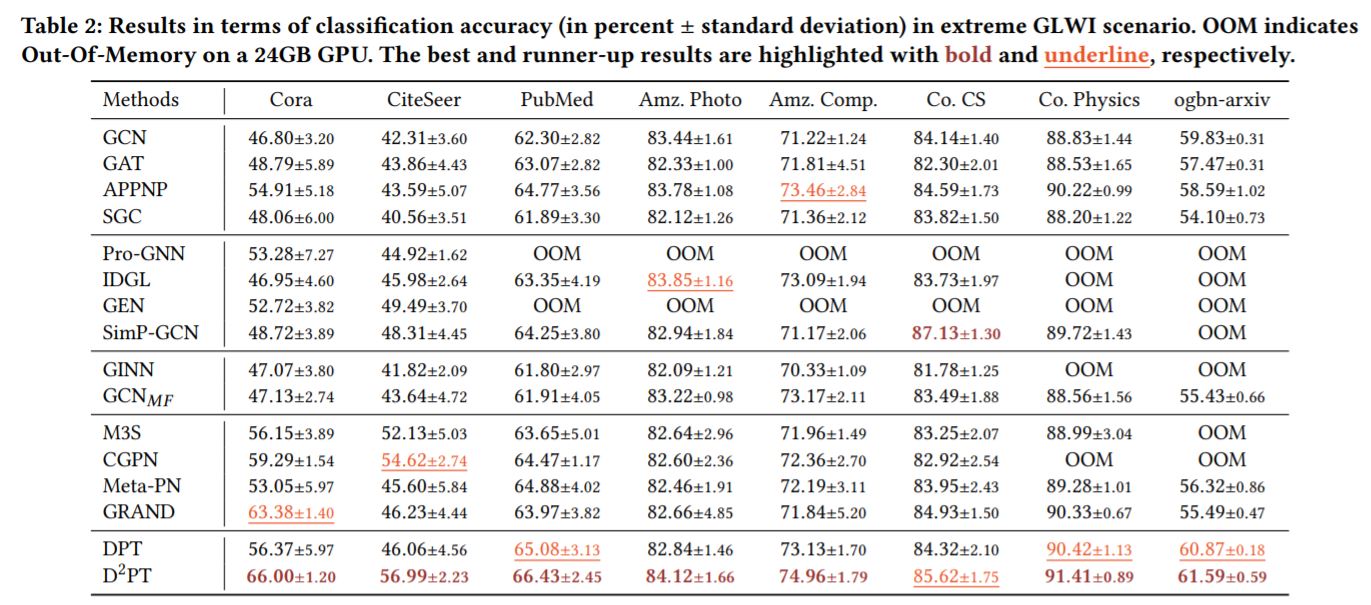
·模型在7/8个数据集上取得了state-of-the-art的测试准确率,在Co.CS数据集取得了第二名的测试准确率。
[注]作者仅在24GB的显卡上运行模型,少数模型在部分任务上撑爆显存,就直接没有计算运行结果,似乎有些降低说服力。
(2)泛化能力——模型泛化到单一弱信息场景(弱结构场景/弱特征场景/弱标签场景)的表现
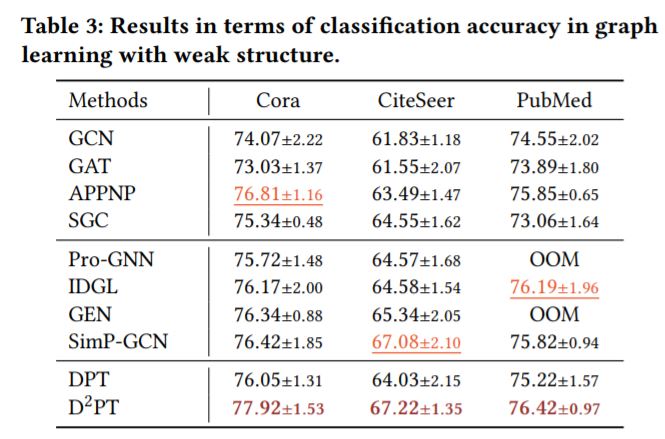
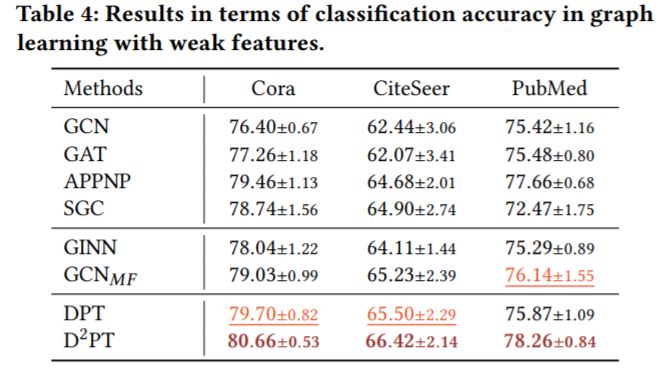
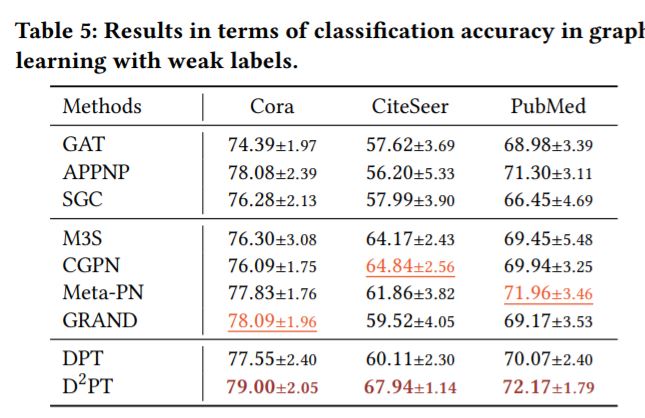
·\(D^2PT\)模型虽然没有针对某个的单一弱信息场景进行特别处理,但是性能好于单独针对某个弱信息场景提出的模型,可见其泛化能力较好,不仅仅适用于极端弱信息的情形。
3.模型的计算速度、空间开销
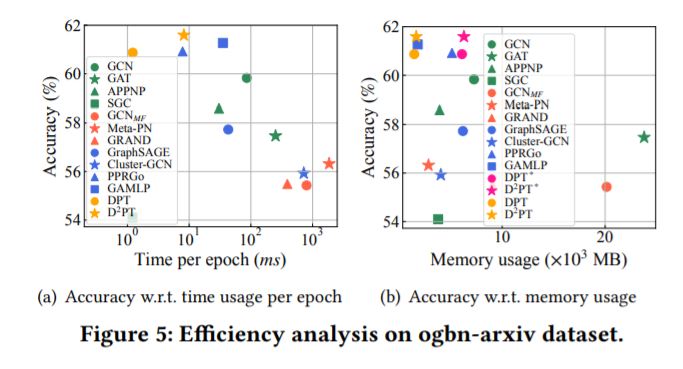
·\(D^2PT\)模型的准确率最高,并且每个epoch的运行时间、内存使用量在所有模型中均相对较低。
4.消融实验——证明各项设计的作用
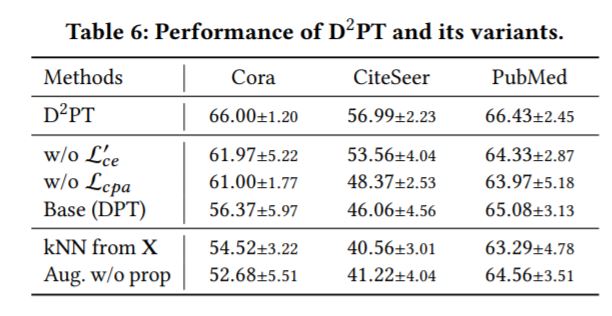
(1)关键设计及其对比条件
·总损失函数中global graph的交叉熵损失项\(L_{ce}'\)--去除该损失项
·原型对比对齐损失\(L_{cpa}\)--去除该损失项
·将original graph经若干轮次propagation操作后的特征\(\mathbf{\bar{X}}\)用于全局\(k\)近邻图构造--改为使用未经传递操作的原始输入特征\(\mathbf{X}\)
(2)实验结果
·分别对各个关键设计进行去除/修改,所得模型的性能均不及\(D^2PT\),证明了各项关键设计的作用。
5.训练轮次与准确度的关系、聚类可视化结果
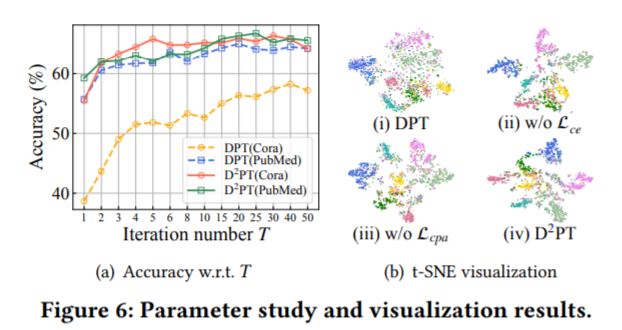
·仅带有图扩散机制,没有全局图、原型对比学习的\(DPT\)模型需要训练更多的epoch,准确率才会达到较好水准;且\(DPT\)准确率不及\(D^2PT\)。
·作者使用t-SNE对高维聚类数据进行降维可视化,可见仅带有图扩散机制的\(DPT\)模型聚类边界最为模糊,分别去除损失项\(L_{cpa}, L'_{ce}\)的\(D^2PT\)聚类结果好于\(DPT\),但部分类别存在重叠情况;相比之下,原版\(D^2PT\)模型聚类可视化效果最佳。
六、未来工作与个人理解
【未来工作】
1.作者认为的未来工作方向
①探索如何解决数据缺陷更严重的GLWI问题。
②将GLWI应用于更多的下游任务(如:图分类、边预测)。
③不完整图数据的无监督学习研究。
2.我认为的未来工作方向
①本文虽然构造了global graph用于提取特征,但最终还是直接使用单个图上的特征进行结点标签预测。应探索如何融合global graph/original graph分别得到的节点特征矩阵,将融合特征矩阵用于结点标签预测,探索这种做法是否能带来进一步的模型性能提升。
②我个人认为基于original graph上的propagated feature\(\bar{\mathbf{X}}\)构造\(k\)近邻全局图,确实是有用的,但效果有可能也是sub-optimal的。可能存在这样一种情形:某个connected component中,结点\(A, B\)间距离为\(5\),原始语义相似度\(sim_{original}(A, B)\)较低,但是经过若干轮的消息传递与融合,二者的propagated feature相似性得到了一定程度的升高;结点\(C\)不在connected component中,与\(A\)的原始语义相似度\(sim_{original}(A, C)\)高于\(sim_{original}(A, B)\),但是\(C\)的自身特性在消息传递中被稀释,导致\(sim_{propagated}(A, B) \gt sim_{propagated}(A, C)\),从而\(C\)可能不在\(A\)的语义相似度\(k\)邻域中。未来工作需要验证这样的情况是否会频繁发生,如果会那么应该提出一种新的\(k\)近邻构造机制,即如果两个结点的原始语义相似度高于某个指定阈值\(\tau_{original}\),则直接互相纳入对方的语义相似\(k\)邻域;如果原始语义相似度低于阈值,再在若干轮propagation后重新计算语义相似度并进行排序。
[注]上述情况不一定普遍,因为邻域在GNN中提供了极其丰富的信息。需要具体实验来验证上述结论。
【个人观点】
1.global graph的本质
(1)本质——全局注意力
·本文使用global graph进行数据增强,本质上可以称得上是一种“全局注意力”。
(2)观点——从图的视角审视序列数据
·我们可以将用于图数据的\(D^2PT\),和用于序列预测任务的经典Transformer进行类比。在序列预测任务中,假如我们把每个token看作图中一个节点,两个相邻token间存在边连接,那么每一段序列数据总是一个连通图。
(3)序列数据、图数据上的全局注意力作用
·对于序列数据而言:由于序列数据总是一个“连通图”,因此每个token都能顺利注意到“图”中其他任何一个结点,都有“全局感受野”。
·对于图数据而言:如果一个大规模的图由于结构不完整(边的缺失),而被分割为若干互不连通的子图,那么某个结点对其他结点的“注意力”只能局限于自己所处的连通子图,“感受野”可能受限,导致感知信息不充分。
(4)global graph的作用
·打破由边的存在与否决定的“感受野受限”问题,让每个结点均拥有“全局感受野”。
[注]作者在文中并未点明global graph的全局注意力本质,但是经过我仔细思考,发现自己的看法应该是十分合理的。
2.经典GNN的一个常见缺陷以及\(D^2PT\)对该缺陷的弥补
[注]基于一阶邻域的传统图注意力机制(GAT, Graph Attention Network)简介

(1)传统图注意力机制的问题
基于第1点分析,我们可以将序列数据视为图数据,并确定了\(D^2PT\)的“全局注意力本质”,下面我们从序列注意力、图注意力的异同点谈起,分析传统图注意力机制的一个问题。
·传统图注意力机制:一次注意力操作中,仅对一阶邻域结点与当前节点的表征,进行注意力权重计算、表征融合。
·序列注意力机制:一次注意力操作中,直接对所有token进行注意力权重计算、表征融合。
·我们举例思考一个问题:一个序列长度为\(7\),设token\(v_1\)和\(v_7\)需要完成信息沟通。在序列注意力机制中,二者仅一次注意力操作即可完成信息沟通目的;但是如果把图注意力机制应用到该序列(视为链条状的图),则需\(6\)步注意力操作,\(v_1\)的表征才能真正到达\(v_7\),而且此时\(v_1\)的表征已经被稀释得很多了,这就导致即使\(v_7\)即使能够注意到\(v_1\),也会存在注意力分散(attention dilution)问题。
·序列注意力机制可以视为针对某种简单图结构的注意力机制,范围局限一些,但是效率很高;传统图注意力机制可以视为针对一般图结构的注意力机制,但与序列注意力机制相比,在效率、作用上肯定存在较大的局限性。
(2)\(D^2PT\)对该缺陷的解决方案
·构建global graph,使得中远距离/互不连通,但语义相似度较高的结点之间的“注意力”不再依赖于边的有无/特征被严重稀释的long range propagation,而是有可能直接通过一步迭代进行信息沟通。
(3)\(D^2PT\)相较于传统图全局注意力的优势
·粗略从网上搜索了两篇早期的全局图注意力文章:1、2,发现它们用于计算语义相似度、打破连通性束缚的特征不够强,可能导致噪声过多,这可能是性能被后来者迅速超越,没有受到太多关注的原因。
·我们再看\(D^2PT\),它不是一种简单的全局注意力机制,而是先进行propagation获得比较健壮的混合特征,为全局注意力的应用提供了坚实的基础;由于图结构的邻域比序列结构复杂很多,图结构中一阶邻域提供的信息可能也比序列结构更丰富,因此\(D^2PT\)使用的并非朴素的“全局注意力”,而是一种经过语义相似度筛选的“选择性全局注意力”;另外,同时运行全局图、原始图这两个“通道”,也是模型不可或缺的一环。
3.观点总结
·global graph作为一种图结构上的“选择性全局注意力”机制,完成了下列两个功能:
(1)打破由边决定的连通性束缚,让每个结点都有和其他任一结点经一步或多步消息传递,实现相互“注意”、进行信息传递的可能。
(2)打破了经典GNN中信息传递局限于局部、扩散速度缓慢的束缚,为中长距离/互不连通,但具有高相似度的节点之间直接进行信息传递提供了可能。
·上述功能的实现有一个前提,就是用于计算注意力系数(语义相似度)的结点特征质量足够高,\(D^2PT\)先进行单通道propagation,之后再进行单通道变双通道,产生global graph,可以提供质量较好的结点特征。
从“选择性全局注意力”观点反思\(D^2PT\),可以发现该模型的设计蕴含了丰富的思想,十分值得学习、研究。当然,想要明显改进模型也不容易,因为强特征、全局注意力的结合是十分精妙的,作进一步优化恐非易事。